A complete screen recording showing the pipeline from git push to zero-downtime production deploy. Includes Grafana dashboard reacting in real time
— THE PROBLEM
What Was Breaking Before I Arrived
→ Engineers were being woken up at 2 AM for alerts that resolved on their own, no filtering, no intelligence
→ When real incidents hit, diagnosis was pure guesswork. Copy-pasting logs into Slack hoping someone knew the answer
→ Critical production incidents sat unacknowledged for 3–4 hours before anyone escalated
→ Payment API failures caused cascading timeouts with no automated detection, just angry customer tickets arriving first
→ No runbooks. No post-mortems. No pattern visibility. Every incident felt like the first time
→ Escalations to leadership happened over WhatsApp, no structure, no timestamps, no accountability
— MY SOLUTION
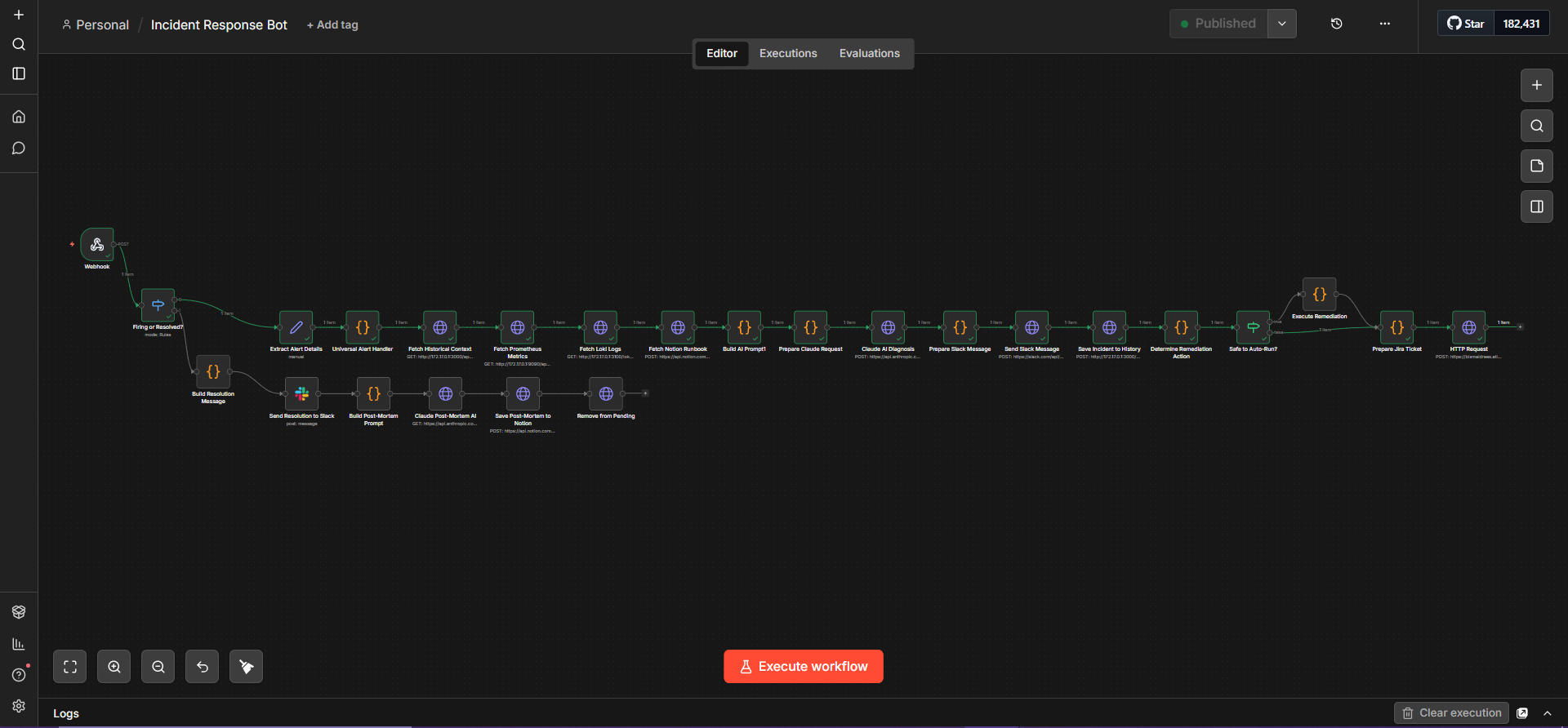
What I Built — Step by Step
01
AI Detection Engine
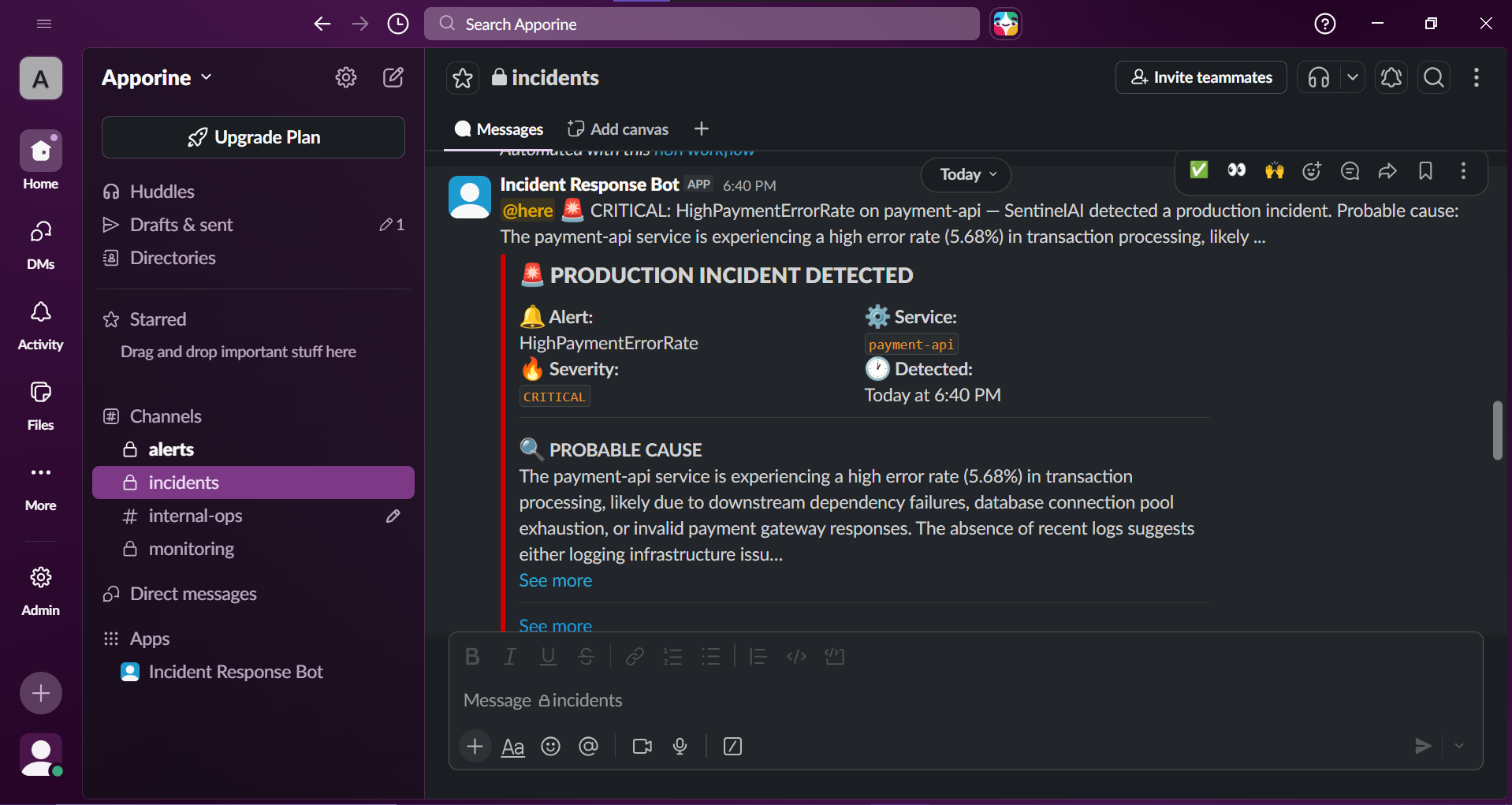
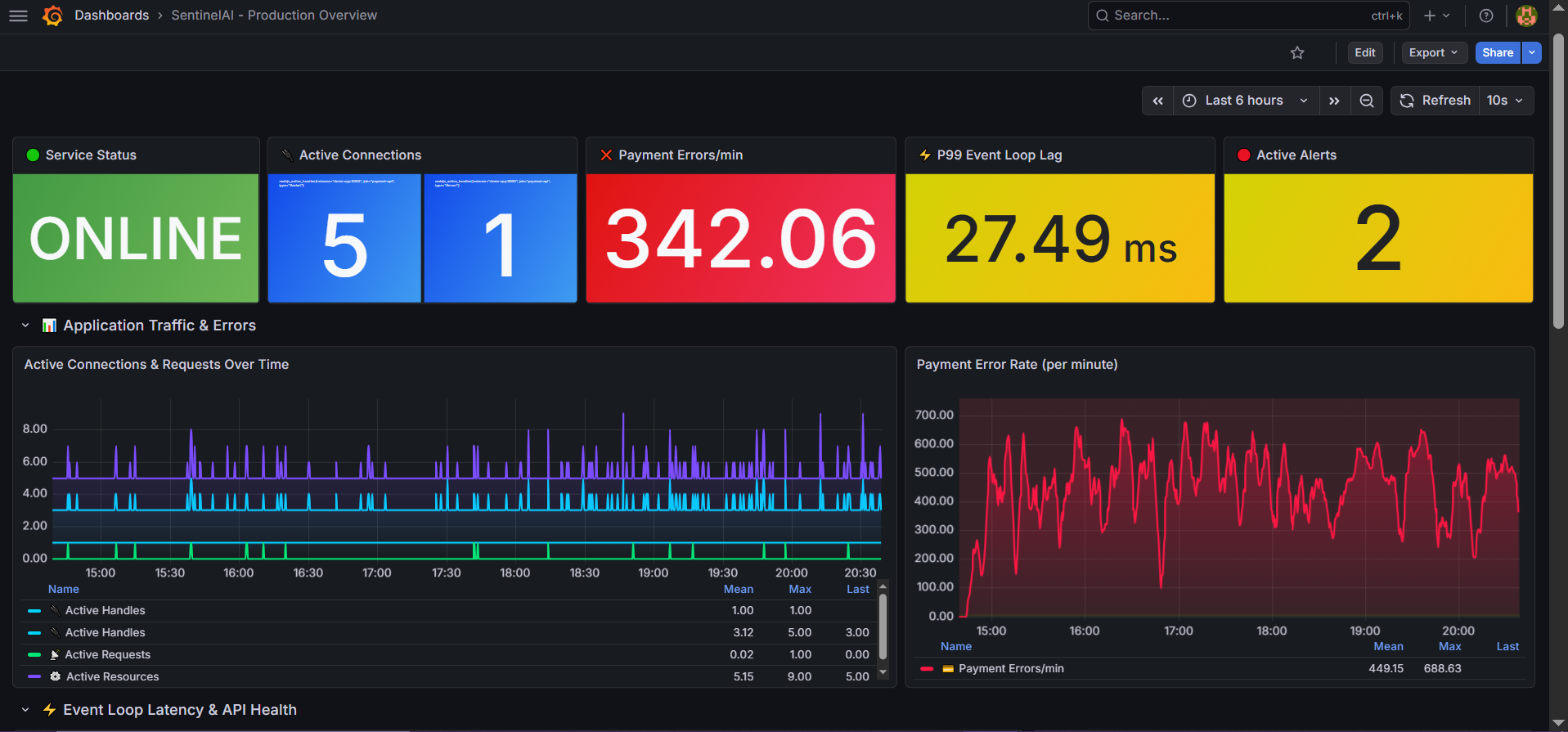
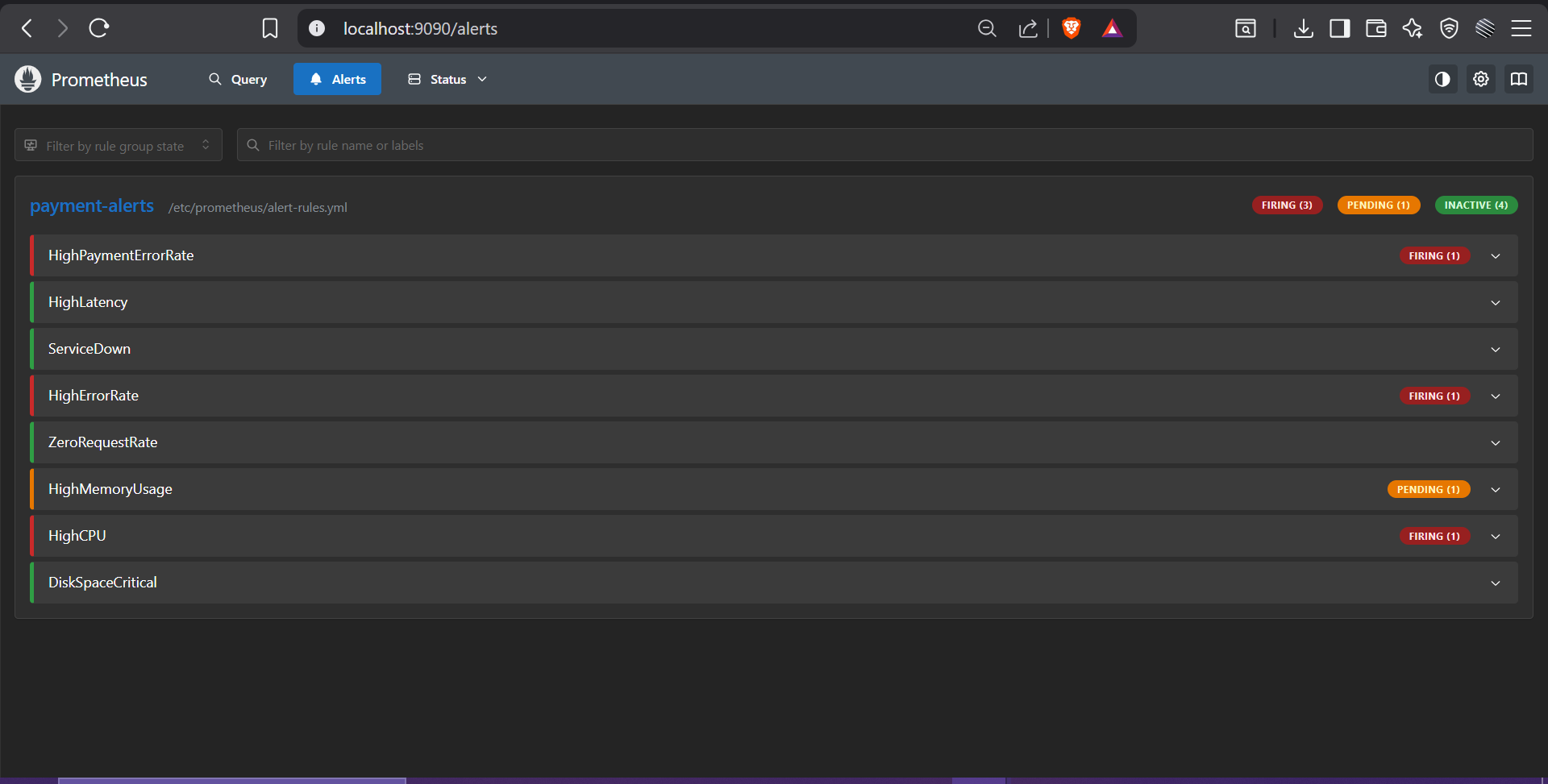
Prometheus alert rules fire within 30 seconds of anomaly. SentinelAI ingests metrics, Loki logs, and historical context simultaneously, no human needed to notice something is wrong.
02
Claude AI Diagnosis
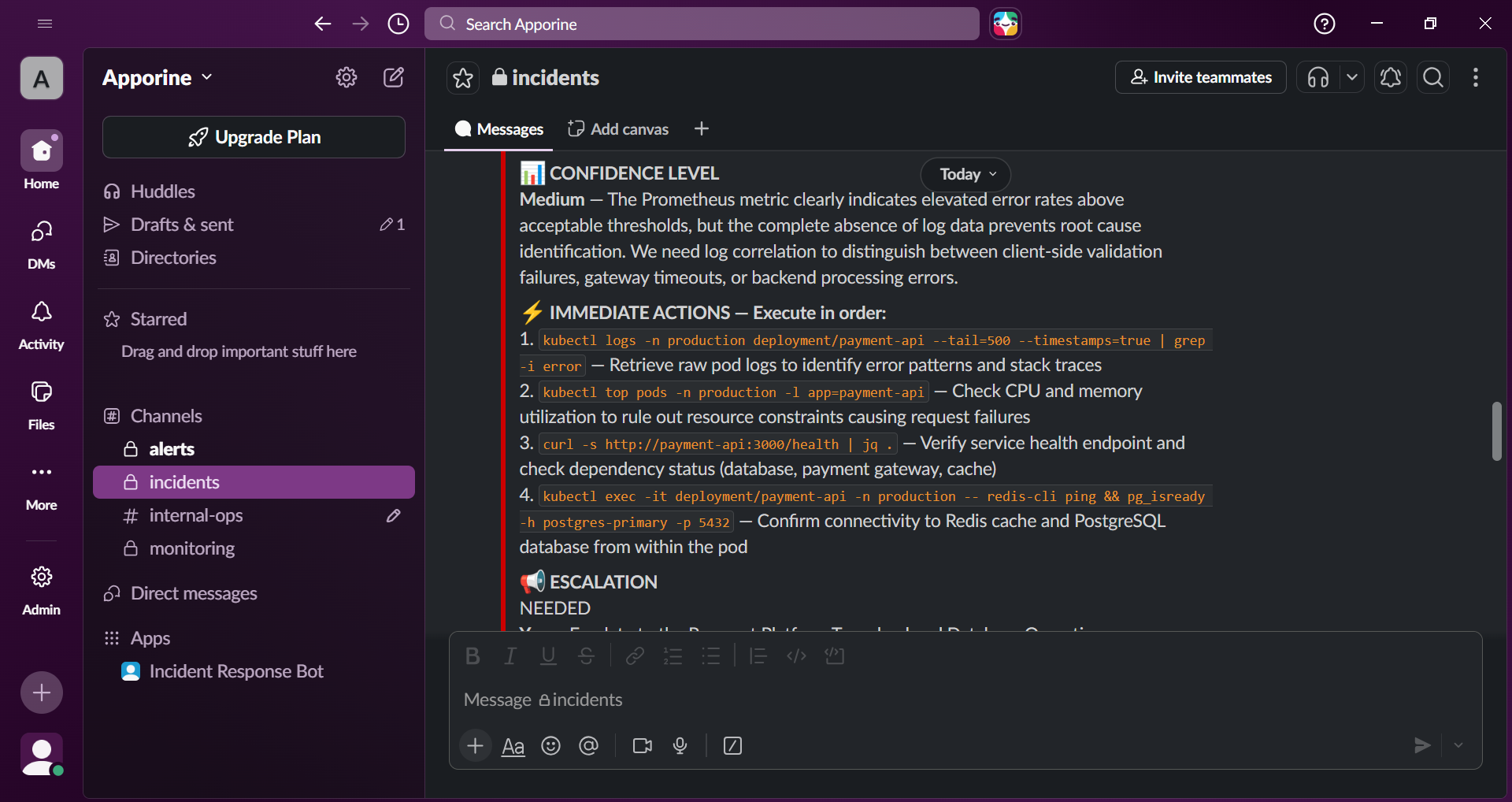
Every alert triggers a Claude-powered root cause analysis. The bot delivers a structured report: probable cause, confidence level, immediate action steps with exact kubectl commands, and escalation recommendation, in one Slack message.
03
Smart Escalation Ladder
n8n escalation monitor checks unacknowledged incidents on a schedule. After threshold, team gets reminded. After longer, manager gets pinged. After critical threshold, CTO receives a formal escalation. All automatic, all logged.
04
Auto-Remediation + Full Audit Trail
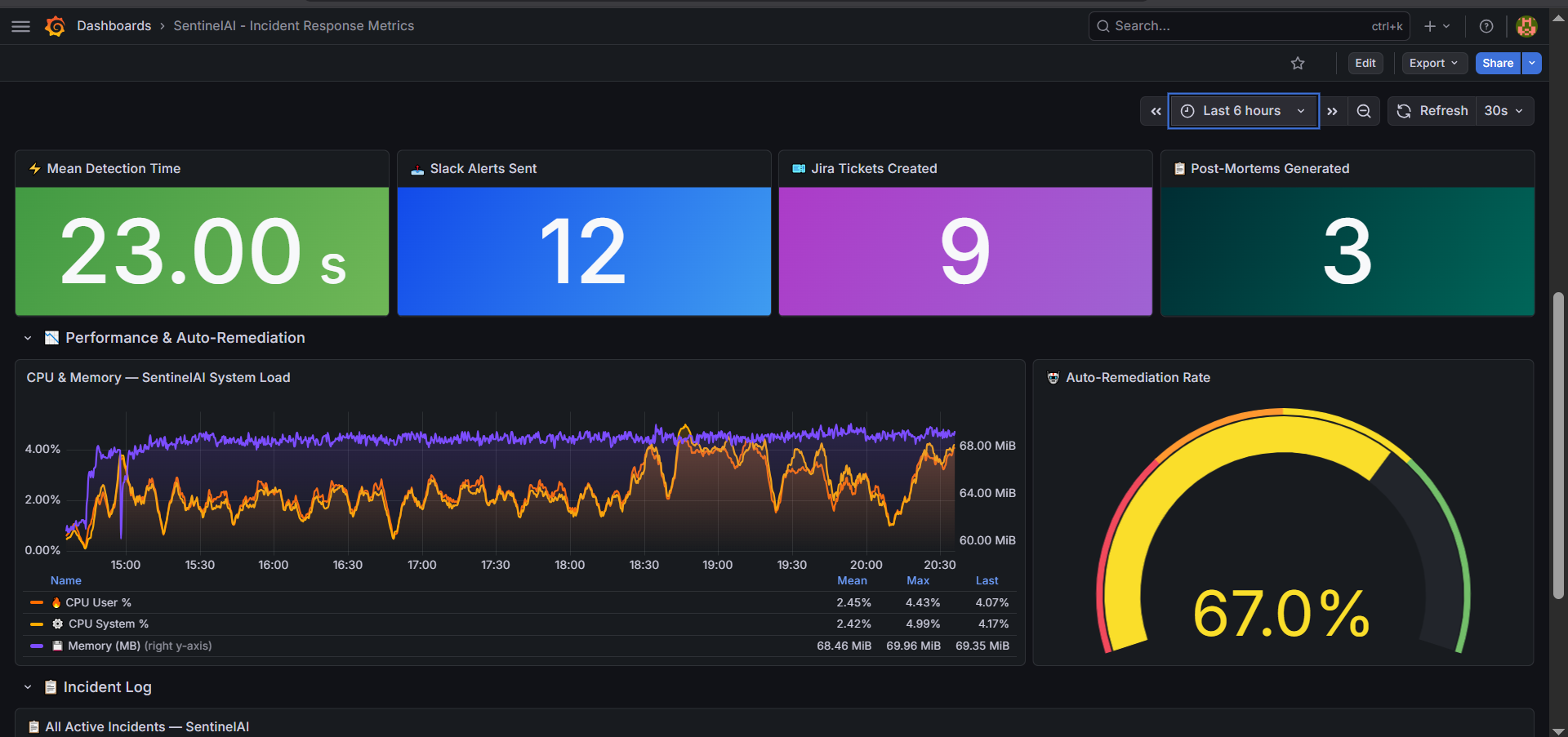
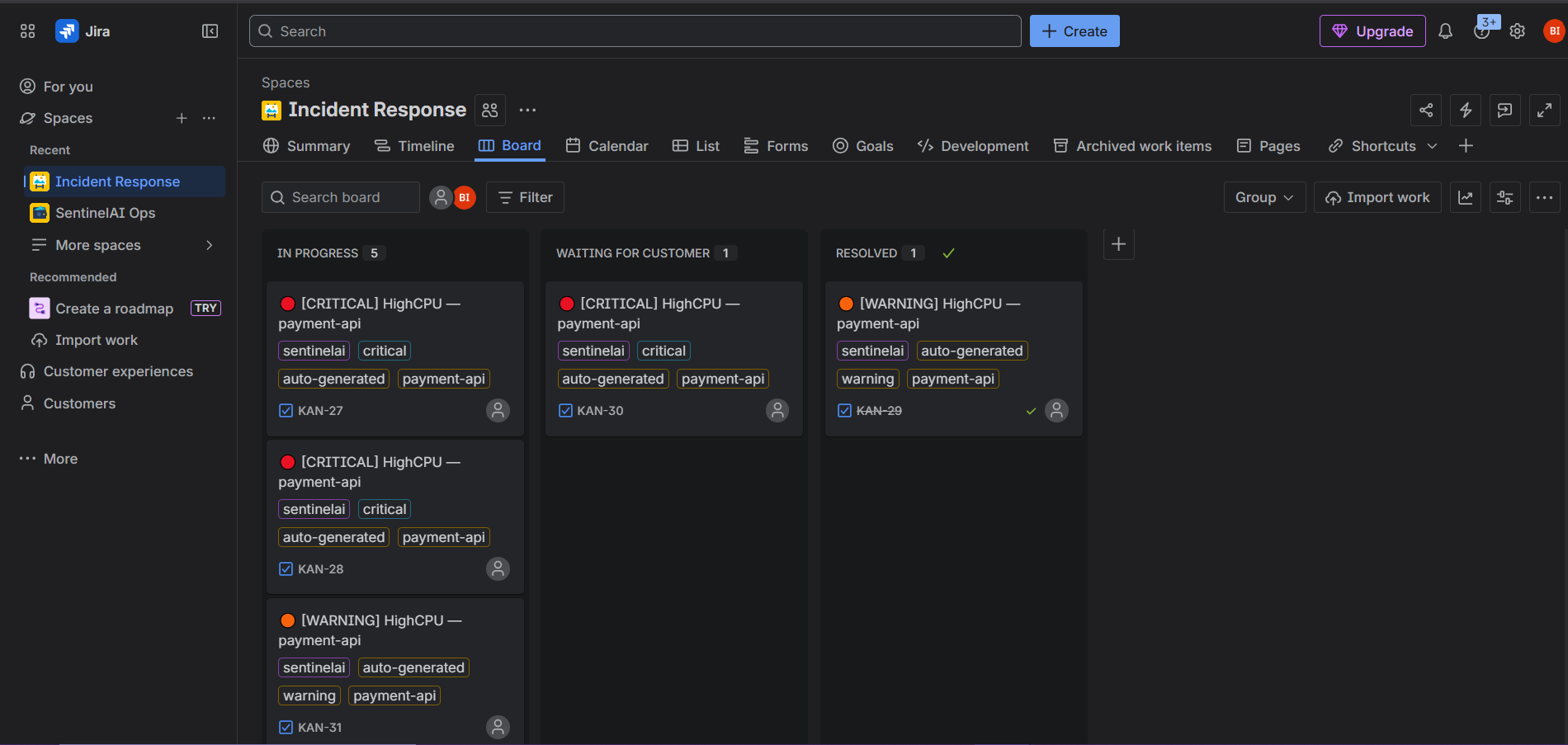
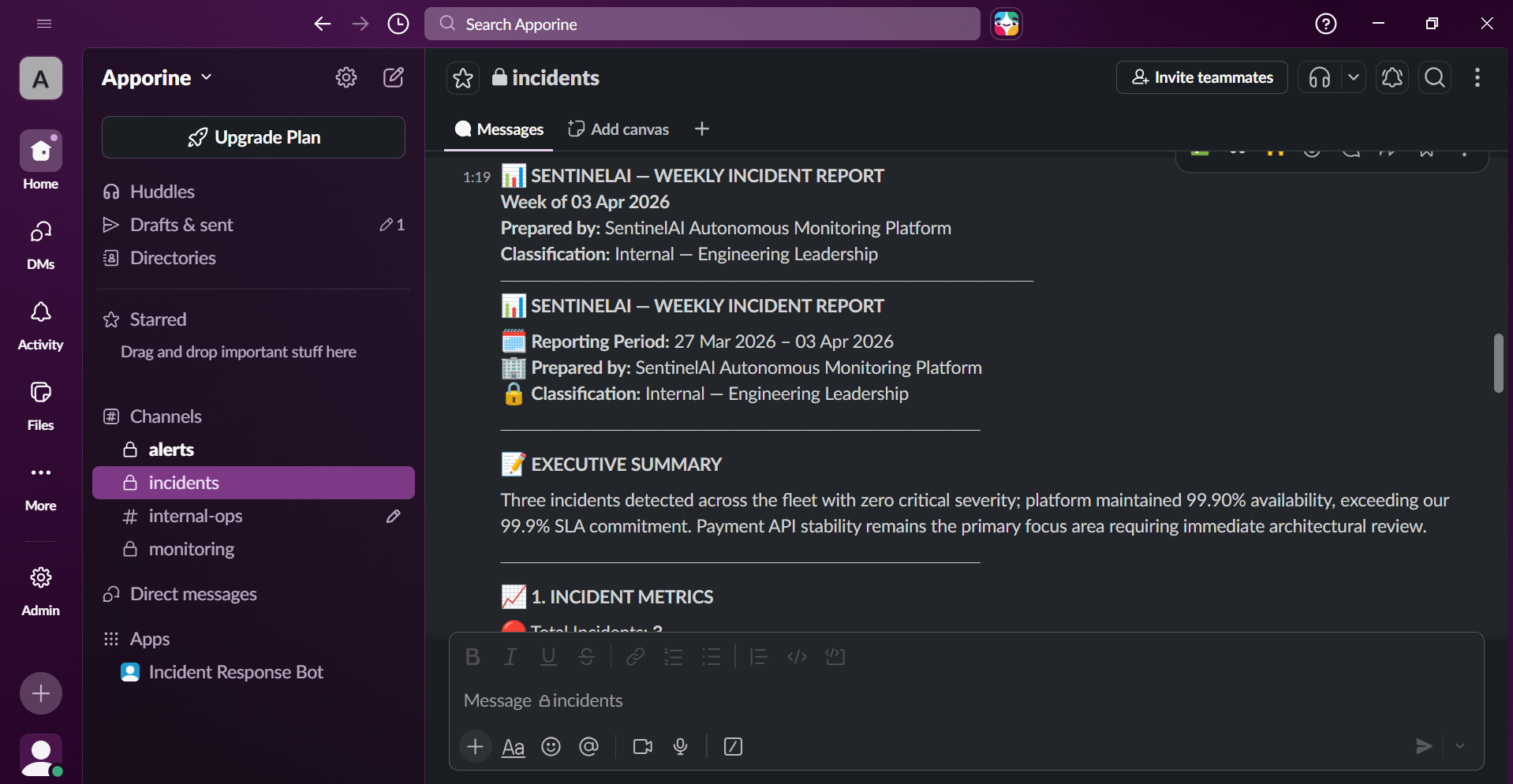
67% of incidents are resolved autonomously. Every incident generates a Jira ticket, updates a Notion runbook, and gets logged to incident history. Weekly AI-written reports land in Slack every Monday at 9 AM.
— The Results
What Changed After Delivery
0s
MEAN DETECTION TIME
From hours of manual monitoring
0%
AI AUTO-RESOLUTION RATE
Incidents closed without human action
0min
MEAN TIME TO RESOLVE
Down from 4+ hour war rooms
0%
Availability
Maintained across all incidents
— Stack Used
Tools & Technologies
Prometheus
Grafana
n8n
Slack
Claude AI (Anthropic)
Slack
Jira
Notion
Node.js
Docker
Webhooks
Loki
Python
— Client Feedback
What the Client Said
★★★★★
Before SentinelAI, our on-call rotation was a nightmare. Engineers were getting paged at 3 AM for things that weren’t even real incidents. Since deployment, 67% of alerts resolve themselves before anyone wakes up. The AI diagnosis messages in Slack are so detailed that even our junior devs know exactly what to do. Bisma didn’t just build us a bot, she gave our team their nights back.
JW
James Whitfield
CTO · FinTech Startup · United States
Verified
Have a similar challenge?
Let's talk about your infrastructure
I read every message personally. No templates. No sales pitch.